FEAFA+: An Extended Well-Annotated Dataset for Facial Expression Analysis and 3D Facial Animation
Wei Gan, Jian Xue, Ke Lu*, Yanfu Yan, Pengcheng Gao and Jiayi Lyu
School of Engineering Science, University of Chinese Academy of Sciences, Beijing 100049, China
INTRODUCTION
Facial expression analysis based on machine learning requires large number of well-annotated data to reflect
different changes in facial motion. Publicly available datasets truly help to accelerate research in this area by
providing a benchmark resource, but all of these datasets, to the best of our knowledge, are limited to rough
annotations for action units, including only their absence, presence, or a five-level intensity according to the
Facial Action Coding System. Even though the intensity information is accessible, these AU annotations with
discrete levels can only suitable for detection tasks or rough intensity estimation tasks. These existing datasets are
not accurate enough to describe subtle intensity variation and enable an AU value regression task. To meet the need
for videos labeled in great detail, we present the FEAFA+ dataset.
STRUCTURE
FEAFA+ consists of two sub-datasets: FEAFA (sub-dataset A) and re-labeled DISFA (sub-dataset B).
- FEAFA: There are 127 posed sequences with 99,356 frames labeled. One hundred and twenty-two participants, including children, young adults and elderly people, were recorded in real-world conditions. All the participants were asked to make the required facial movements in the Facial Expression Data Recording and Labeling Protocal.
- Re-labeled DISFA: There are 27 spontaneous sequences with 130,828 frames re-labeled.
The original data were recorded using a specific stereo-vision system in a specific environment
and the participants were mainly young adults of various races.
OBTAINING THE DATA
We make FEAFA+ dataset available for academic research purposes. However, as it involves a lot of personal privacy,
we only send the data to approved researchers. To access the dataset for research (noncommercial use), please send an
email to luk@ucas.ac.cn with a signed AGREEMENT.
Please note that any commercial use of the dataset is prohibited.
FACIAL EXPRESSION DATA RECORDING AND LABELING PROTOCOL
We provide a protocol for facial expression data recording and labeling for the participants to follow when their facial behaviors were recorded by the web cameras. This protocol not only includes how to label the AUs in every image but also illustrates how to elicit the required expression. The protocol text can be downloaded here:
[English Version | Chinese Version].
LABELING TOOL
To label AUs faster and more conveniently, we developed a software called ExpreQuantTool (Expression Quantification Tool), which is specifically designed for labeling data more efficiently. The following figure shows the main GUI of our software. On the right side of it, the generated expression blendshape of a virtual character mimicking the expression of the subject of the frame in the Expression Visualization window is shown.
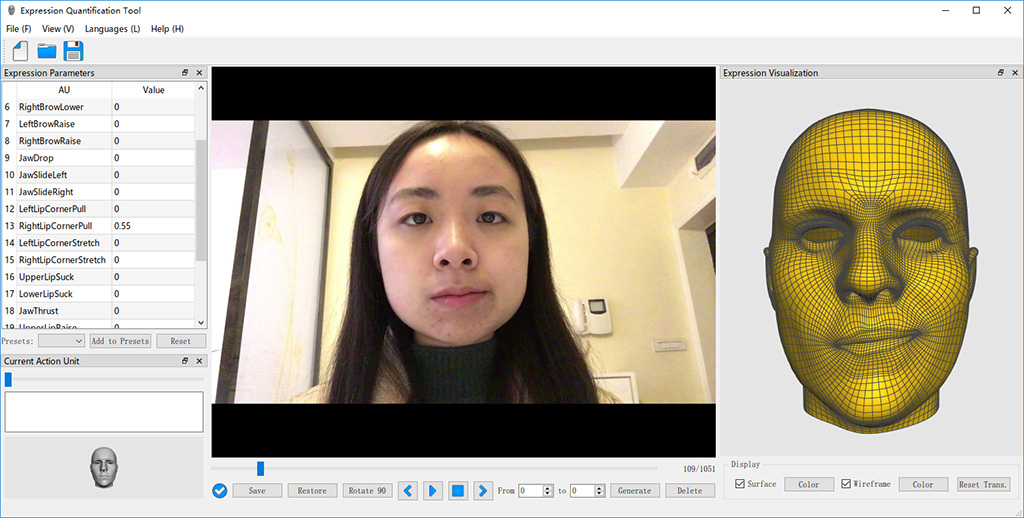
Main GUI of ExpreQuantTool
Please contact Prof. Ke LU (luk@ucas.ac.cn) if you need this tool.
Main GUI of ExpreQuantTool
DEMO
We also developed a demo software for baseline system test. Here are the videos which demonstrate the real-time estimation of AU values from a common web camera and reconstruction of the corresponding expression on a 3D model, running on the baseline system provided by our demo software. The first video (baseline_demo.mp4) illustrates an ordinary usage scenario: capture live facial expression, regress the AU values and reproduce the expression on a 3D model in real-time. The second video (baseline_demo_vchar.mp4) was produced by capturing a low resolution video playing on a LCD screen and transferring the expression to a virtual character based on the regressed AU values, using a low-end webcam, which shows the good performance of our parameter system and dataset in complex environments. Please note that the face landmarks displayed in the live camera window are only used to locate the face in the frame and calculate the head pose, NOT used to get AU values.
[baseline_demo.mp4 | baseline_demo_vchar.mp4].
PUBLICATIONS
- Wei Gan, Jian Xue, Ke Lu*, Yanfu Yan, Pengcheng Gao and Jiayi Lyu. FEAFA+: An Extended Well-Annotated Dataset for Facial Expression Analysis and 3D Facial Animation. Fourteenth International Conference on Digital Image Processing (ICDIP 2022), Wuhan, China, May 20-23, 2022. Proceedings of SPIE Vol. 12342, 1234211:1-10. DOI: 10.1117/12.2643588
- Wei Gan, Jian Xue, Ke Lu*, Yanfu Yan, Pengcheng Gao and Jiayi Lyu. FEAFA+: An Extended Well-Annotated Dataset for Facial Expression Analysis and 3D Facial Animation. arXiv:2111.02751, 4 Nov. 2021
- Yanfu Yan, Ke Lu, Jian Xue*, Pengcheng Gao and Jiayi Lyu. FEAFA: A Well-Annotated Dataset for Facial Expression Analysis and 3D Facial Animation. arXiv:1904.01509, 2 Apr. 2019.
- Yan Yanfu, Lyu Ke, Xue Jian*, Wang Cong, and Gan Wei. Facial Animation Method Based on Deep Learning and Expression AU Parameters. Journal of Computer-Aided Design & Computer Graphics, Vol. 31, No. 11, pp. 1973-1980, 2019. DOI: 10.3724/SP.J.1089.2019.17682
- Yanfu Yan, Ke Lu, Jian Xue*, Pengcheng Gao, Jiayi Lyu. FEAFA: A Well-Annotated Dataset for Facial Expression Analysis and 3D Facial Animation. 2019 IEEE International Conference on Multimedia & Expo Workshops, ICMEW 2019, pp. 96-101, Shanghai, China, Jul. 8-12, 2019. DOI: 10.1109/ICMEW.2019.0-104
Copyright (C) 2021-2023 University of Chinese Academy of Sciences, All Rights Reserved.